Видео с ютуба Batch 1 Inference
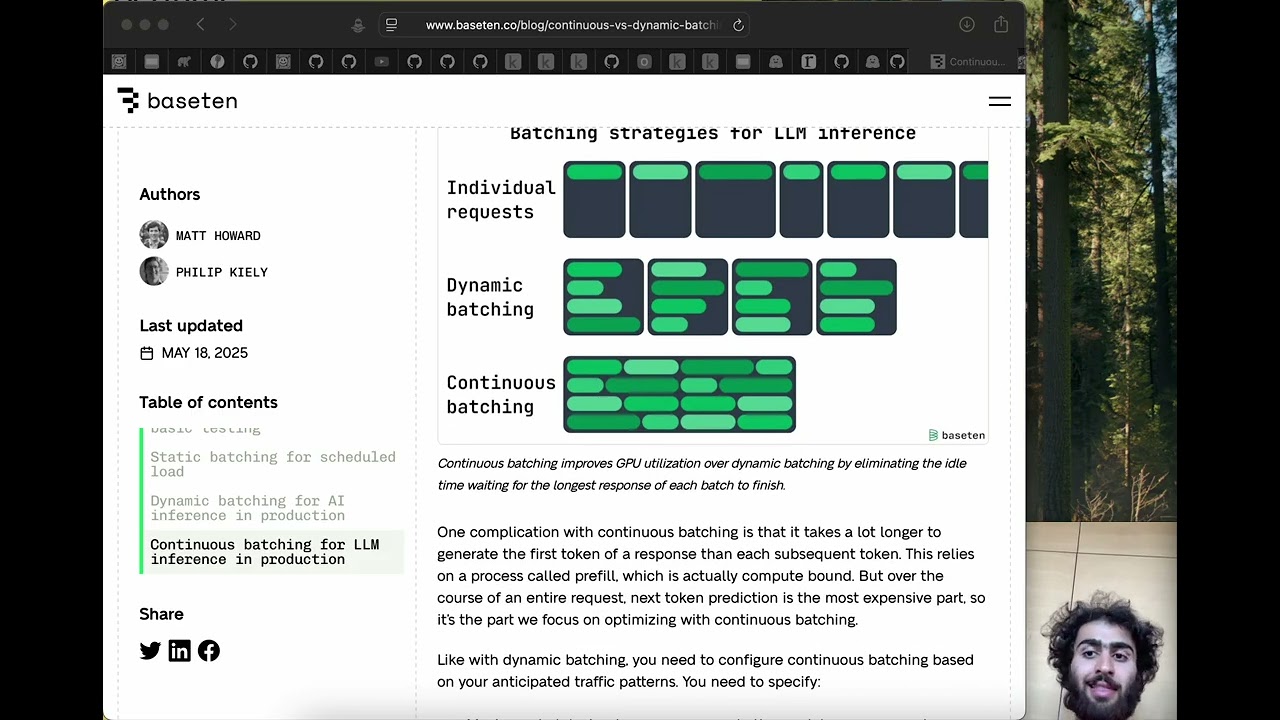
Gentle Introduction to Static, Dynamic, and Continuous Batching for LLM Inference

Stop Using Real-Time AI for Everything — Try Batch Inference Instead

Batch Inference for Open-Source LLMs: Faster, Cheaper, Scalable

Scaling Generative AI: Batch Inference Strategies for Foundation Models

Batch vs Real-time Inference Explained | Model Serving & Inference | ML System Design

What is vLLM? Efficient AI Inference for Large Language Models
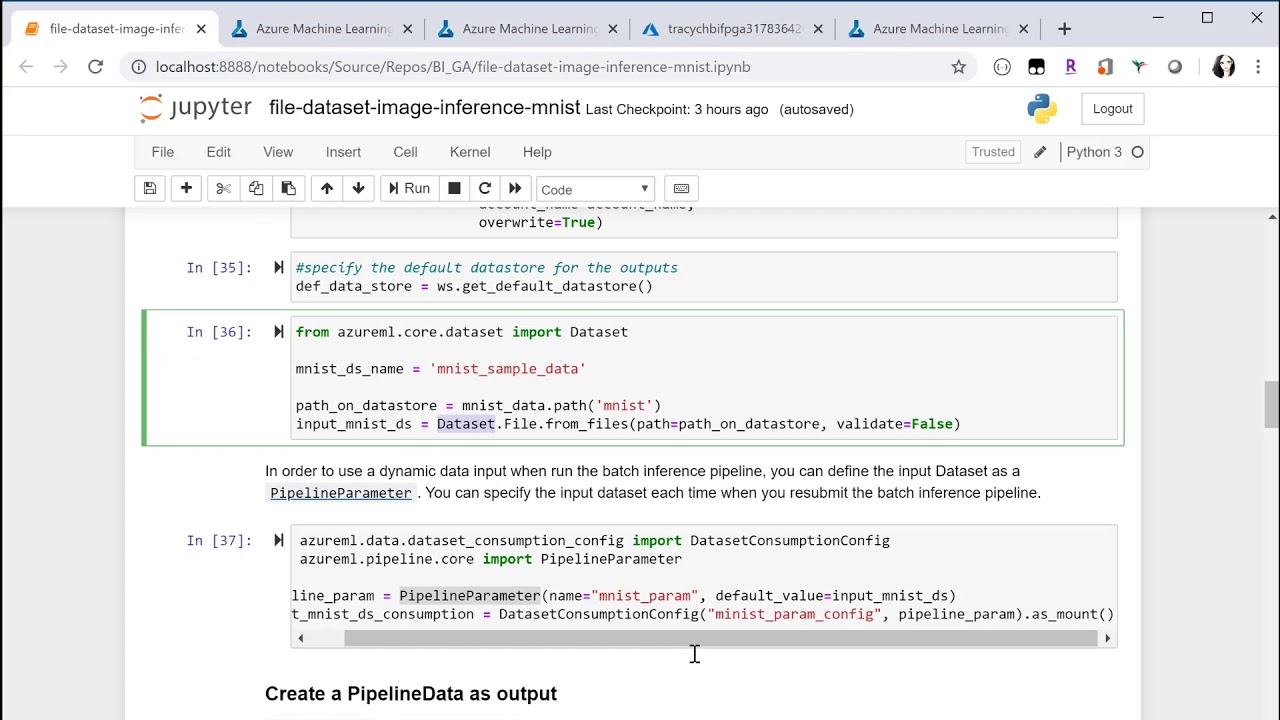
How to do Batch Inference using AML ParallelRunStep

AI Inference: The Secret to AI's Superpowers

Faster LLMs: Accelerate Inference with Speculative Decoding

LLM Batch Inference in Python with Ray Data: Run Large Eval Jobs Faster

Optimize LLM inference with vLLM

Разработка системы пакетного вывода — вопрос проектирования антропической и открытой системы иску...

Deep Dive: Optimizing LLM inference

Batch Inference using Azure Machine Learning

Batch vs. Real-Time Inference Explained

Together AI Unveils Batch Inference API Updates for 2025

Пакетный вывод модели в Foundry с помощью Pipeline Builder

Offline LLM Inference with the Bedrock Batch API

Освоение оптимизации вывода LLM: от теории до экономически эффективного внедрения: Марк Мойу
LLM Inference Optimization Explained | Quantization, Batching & Parallelism